Adding Content from the Global Knowledge Base
Navigate to Knowledge Base > Web Pages & Docs in the left sidebar to access your team’s central content library. From here, you can add individual web pages or upload documents.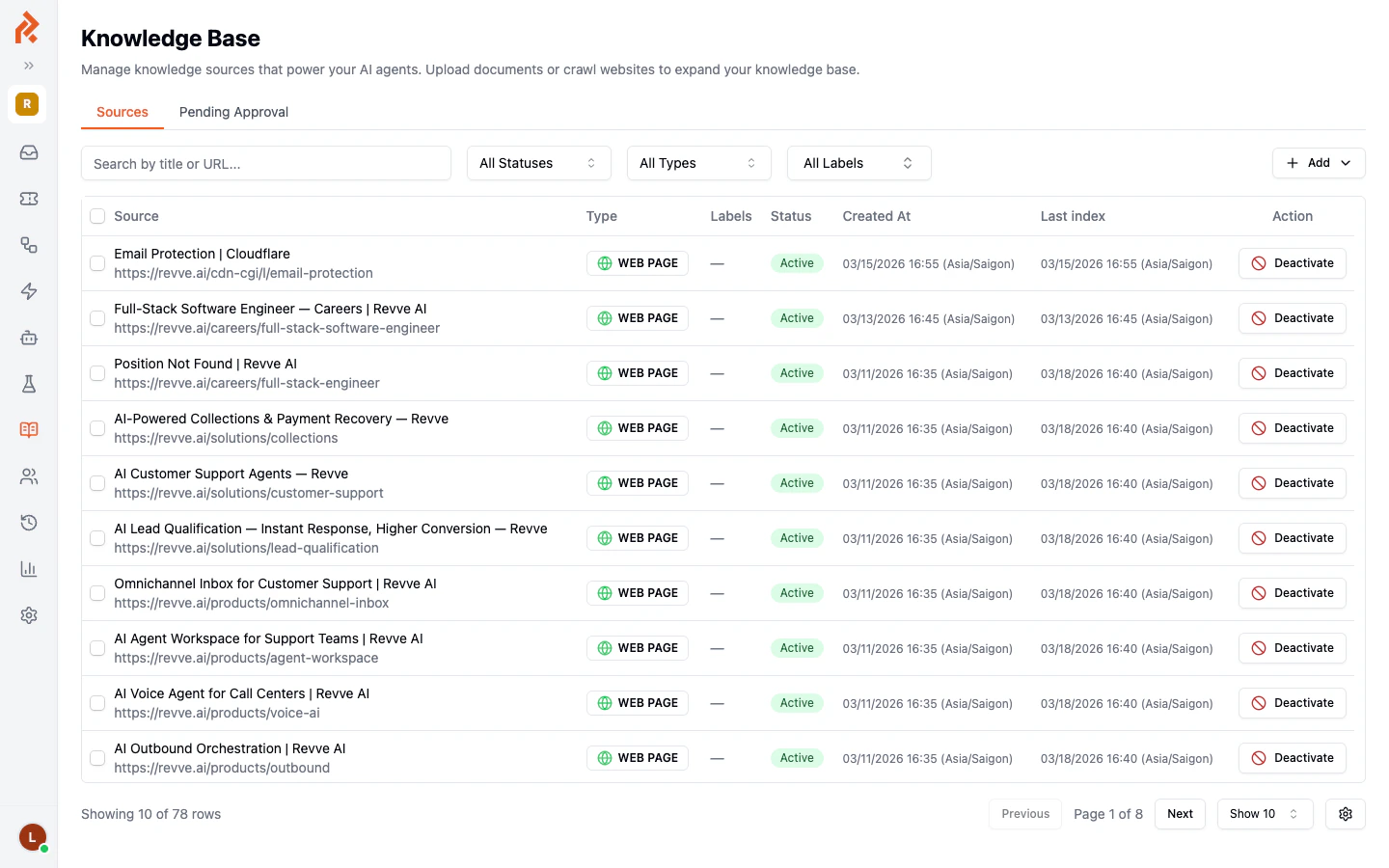
Adding a Web Page
- Click the Add button in the top-right area of the Knowledge Base page.
- Select Add Web Page from the dropdown menu.
- Enter the full URL of the page you want to add (for example,
https://yourcompany.com/pricing). - Click Save. Revve will fetch the page content and index it for your agent.
Uploading a Document
- Click the Add button.
- Select Upload Document from the dropdown menu.
- Choose a file from your computer.
- Click Upload. The document will be processed and added to your knowledge base.
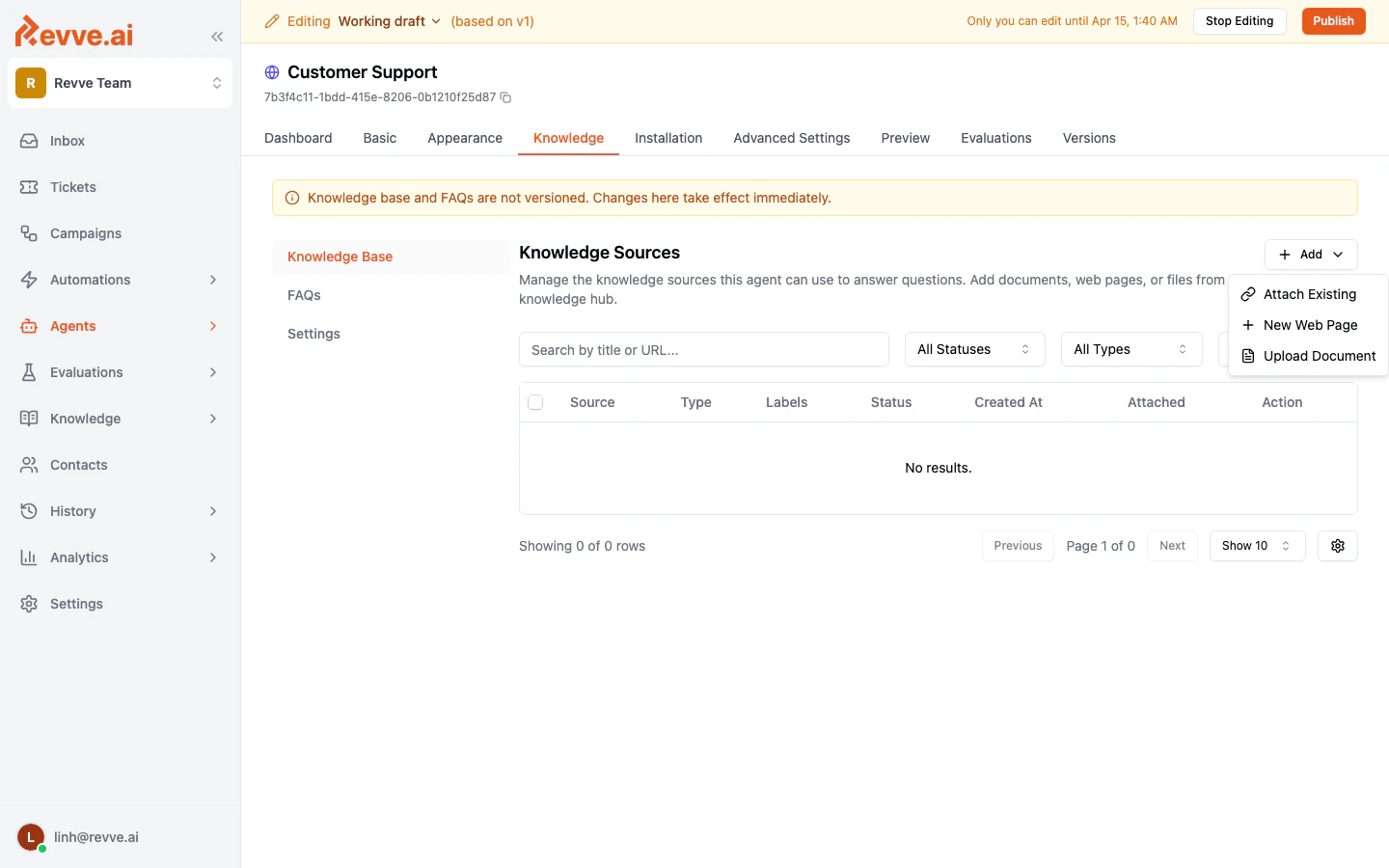
Adding Content from a Chat Agent
You can also add knowledge sources directly from within a specific chat agent:- Open your chat agent and go to the Knowledge tab.
- Click Start Editing to enable changes.
- Click the Add button to add a web page or upload a document.
Managing Knowledge Sources
Each source in your knowledge base has the following attributes:Filtering and Searching
Use the filters at the top of the sources table to narrow your view:- Search bar — Search by title or URL.
- All Statuses — Filter by Active or Inactive status.
- All Types — Filter by Web Page or Document.
- All Labels — Filter by label tags.
Activating and Deactivating Sources
Click the Deactivate button next to any source to temporarily remove it from your agent’s knowledge without deleting it. You can reactivate it later to make it available again.Pending Approval
If you have enabled the “Require approval before indexing” option on a crawler, newly discovered pages will appear under the Pending Approval tab. You can review and approve them before they become available to your agents.Website Crawlers
For websites with many pages, manually adding each URL is impractical. Website crawlers automatically discover and index pages across an entire domain.Viewing Crawlers
Navigate to Knowledge Base > Website Crawlers in the left sidebar to see all configured crawlers.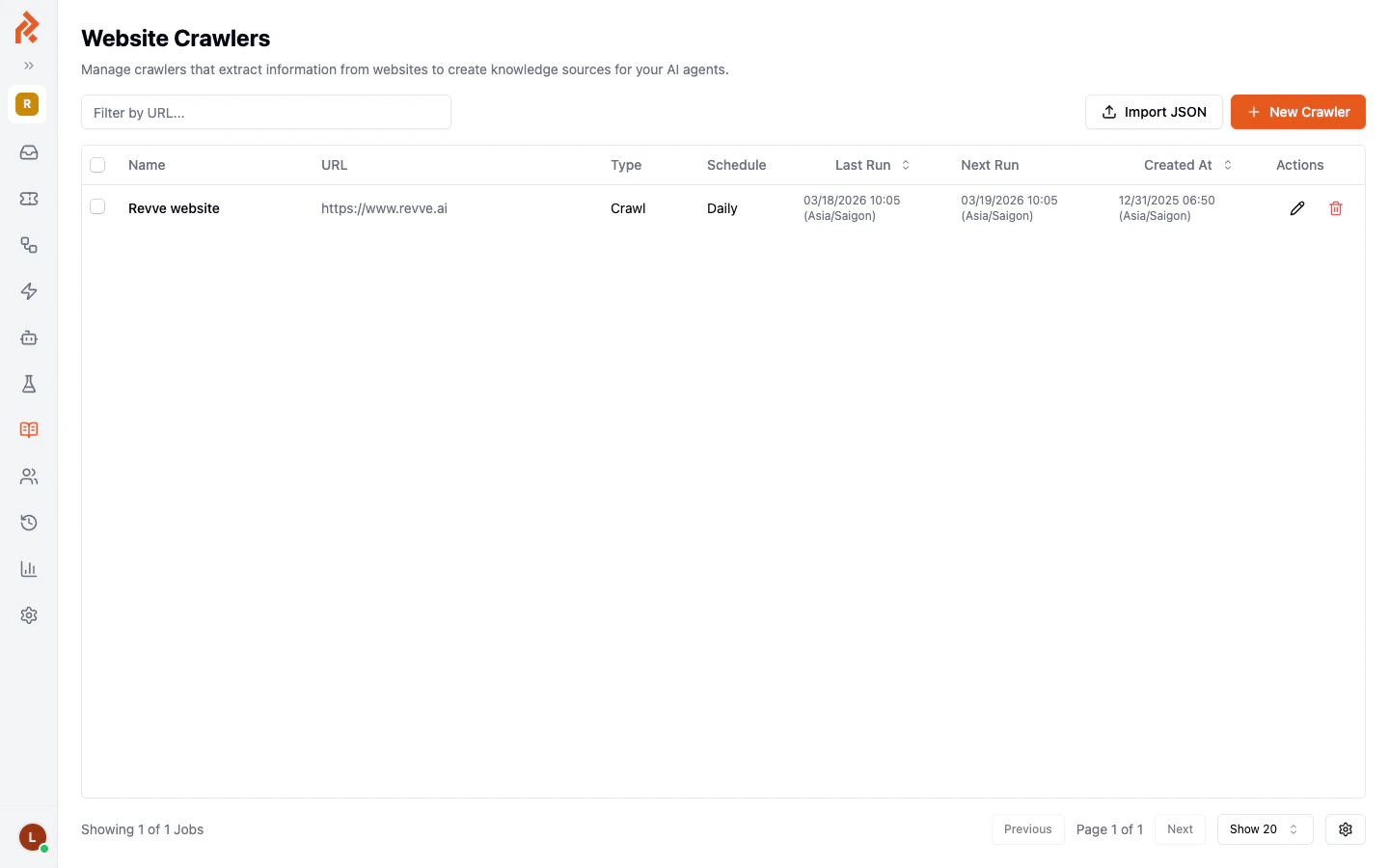
Creating a New Crawler
- Click the New Crawler button.
- Fill in the configuration:
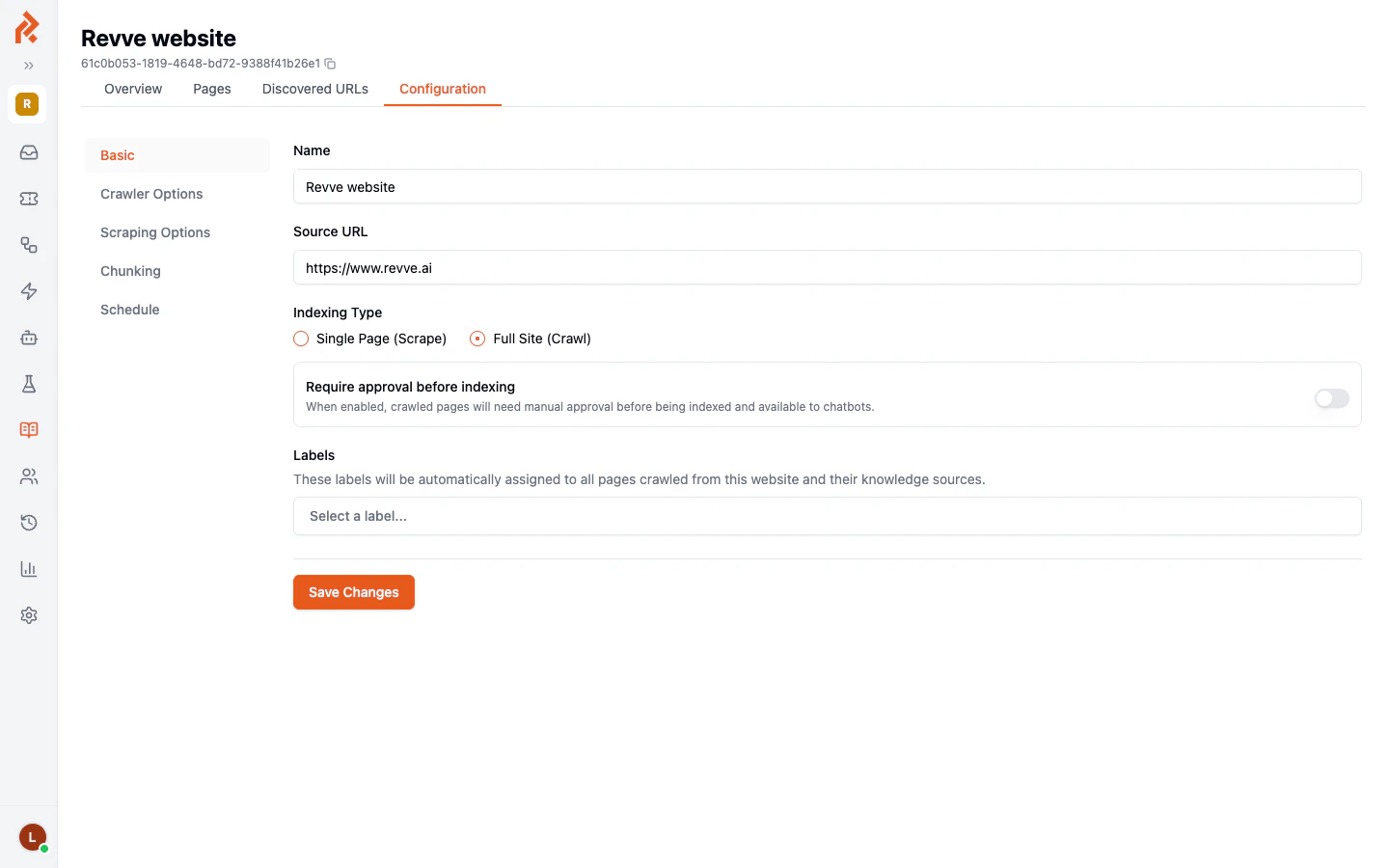
Crawler Schedules
Crawlers have two independent schedules: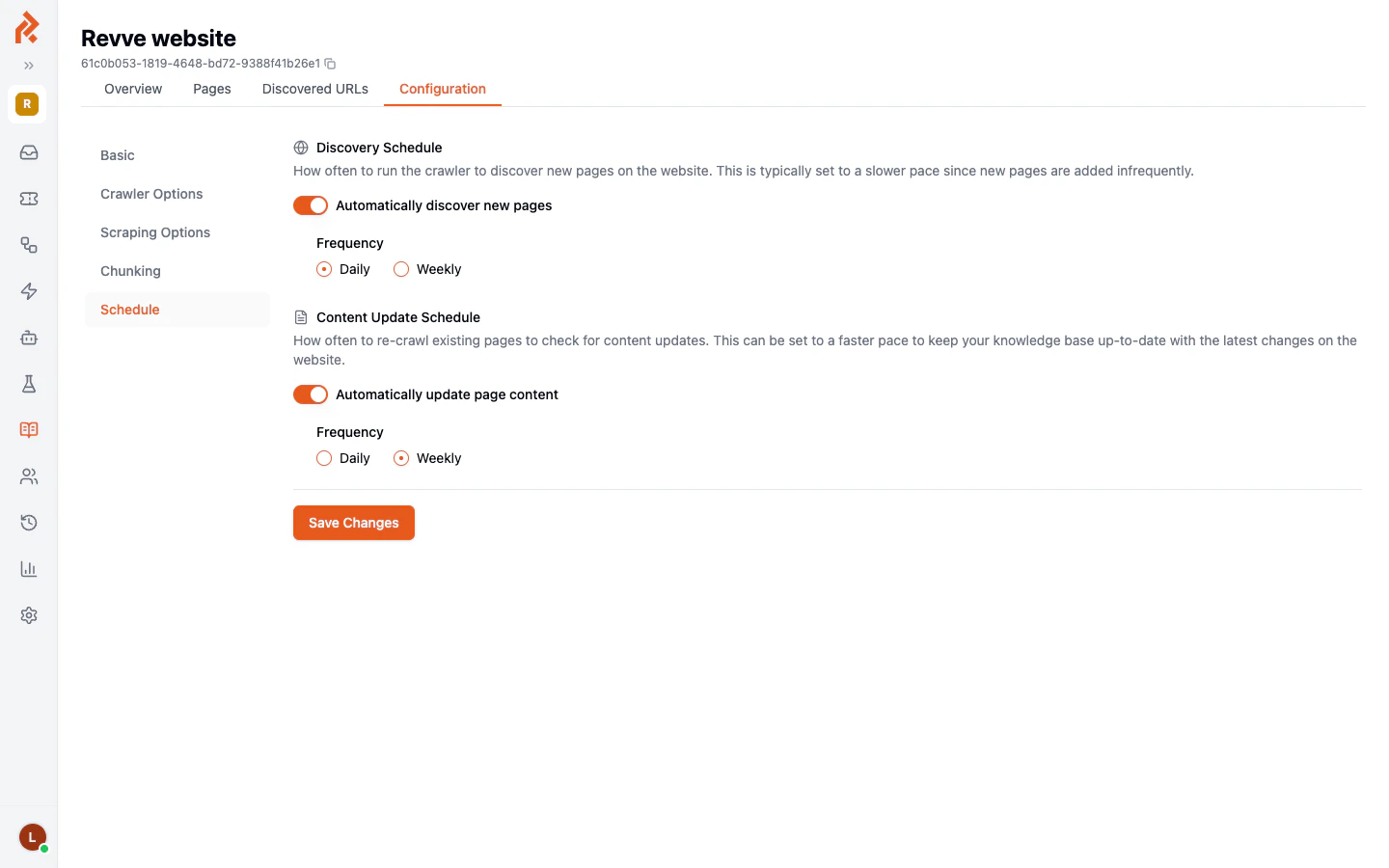
Crawler Tabs
Each crawler has additional tabs for deeper management:Best Practices
- Use crawlers for websites, manual uploads for documents. Crawlers are designed for web content. Use the Upload Document option for PDFs, Word files, and other non-web content.
- Enable approval for large sites. If your website has hundreds of pages, enable the approval requirement so you can review which pages get indexed.
- Set up content update schedules. If your website changes frequently (e.g., a help center with regular updates), configure the Content Update Schedule to re-crawl weekly or daily.
- Label your sources. Labels help you organize content by topic, product, or department, making it easier to manage which agents use which content.
- Check the Last Index date. If a source has not been re-indexed recently, the agent may be using outdated information. Re-index manually or adjust the crawler schedule.
Next Steps
- Managing FAQs — Create question-and-answer pairs for common queries.
- Knowledge Gaps — See what questions your agent could not answer.